
集合演算子 「UNION」
「UNION」句を使用することにより、SELECTの結果を統合することができます。
ちなみに集合演算子を使った場合、基本的に重複行は抽出されません。
「UNION」の構文
以下が、「UNION」の基本的な構文です。
SELECT 列1, 列2,・・・ FROM <テーブル名1> UNION SELECT 列1, 列2,・・・ FROM <テーブル名2>;
検証用のデータの用意
以下の2つのテーブルとデータを使って「UNION」の動きを見ていきます。
| id | name | address |
|---|---|---|
| 001 | いるか | 海 |
| 002 | うさぎ | 陸 |
| 003 | ぺんぎん | 空 |
| 004 | いるか | 海 |
| id | name | address |
|---|---|---|
| 001 | いるか | 海 |
| 002 | うさぎ | 陸 |
| 005 | ふくろう | 空 |
「ANIMAL1テーブル」と「ANIMAL2テーブル」を「UNION」した際のイメージ
「ANIMAL1テーブル」と「ANIMAL2テーブル」の2つのテーブルのすべてのレコードを取得して「UNION」すると以下のような結果が得られます。
注目してほしい点は、ID「001」の「いるか」とID「002」の「うさぎ」のレコードは重複していましたが、「UNION」すると重複行が排除されています。
| id | name | address |
|---|---|---|
| 001 | いるか | 海 |
| 002 | うさぎ | 陸 |
| 003 | ぺんぎん | 空 |
| 004 | いるか | 海 |
| 005 | ふくろう | 空 |
検証用データのSQL
--animal1テーブルとデータの作成
CREATE TABLE animal1
(
id VARCHAR2(10)
,name VARCHAR2(20)
,address VARCHAR2(20)
);
INSERT INTO animal1 ( id, name, address ) VALUES ('001', 'いるか', '海');
INSERT INTO animal1 ( id, name, address ) VALUES ('002', 'うさぎ', '陸');
INSERT INTO animal1 ( id, name, address ) VALUES ('003', 'ぺんぎん', '空');
INSERT INTO animal1 ( id, name, address ) VALUES ('004', 'いるか', '海');
----animal2テーブルとデータの作成
CREATE TABLE animal2
(
id VARCHAR2(10)
,name VARCHAR2(20)
,address VARCHAR2(20)
);
INSERT INTO animal2 ( id, name, address ) VALUES ('001', 'いるか', '海');
INSERT INTO animal2 ( id, name, address ) VALUES ('002', 'うさぎ', '陸');
INSERT INTO animal2 ( id, name, address ) VALUES ('005', 'ふくろう', '空');
検証用データの実行結果
SQL> CREATE TABLE animal1
2 (
3 id VARCHAR2(10)
4 ,name VARCHAR2(20)
5 ,address VARCHAR2(20)
6 );
表が作成されました。
SQL> INSERT INTO animal1 ( id, name, address ) VALUES ('001', 'いるか', '海');
1行が作成されました。
SQL> INSERT INTO animal1 ( id, name, address ) VALUES ('002', 'うさぎ', '陸');
1行が作成されました。
SQL> INSERT INTO animal1 ( id, name, address ) VALUES ('003', 'ぺんぎん', '空');
1行が作成されました。
SQL> INSERT INTO animal1 ( id, name, address ) VALUES ('004', 'いるか', '海');
1行が作成されました。
SQL> CREATE TABLE animal2
2 (
3 id VARCHAR2(10)
4 ,name VARCHAR2(20)
5 ,address VARCHAR2(20)
6 );
表が作成されました。
SQL> INSERT INTO animal2 ( id, name, address ) VALUES ('001', 'いるか', '海');
1行が作成されました。
SQL> INSERT INTO animal2 ( id, name, address ) VALUES ('002', 'うさぎ', '陸');
1行が作成されました。
SQL> INSERT INTO animal2 ( id, name, address ) VALUES ('005', 'ふくろう', '空');
1行が作成されました。
「UNION」の実行例
イメージを掴むためにベン図を書いてみました。
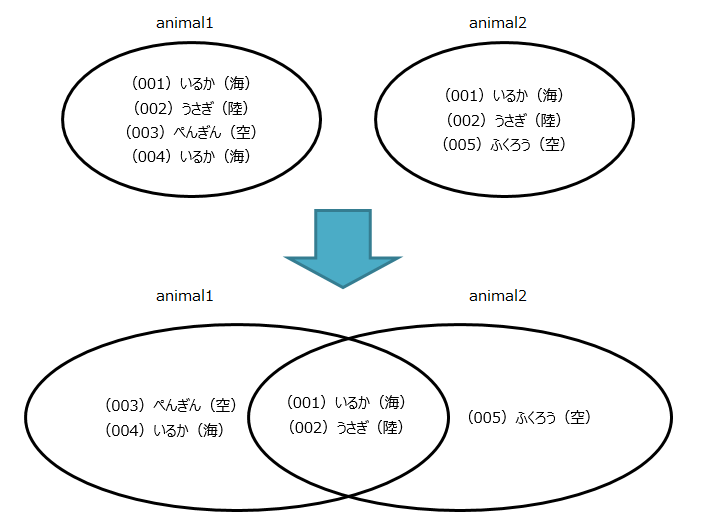
「UNION」のSQL
以下のSQLを実行してみましょう。
SELECT id, name ,address FROM animal1 UNION SELECT id, name ,address FROM animal2;
「UNION」の実行結果
SQL> SELECT id, name ,address FROM animal1 2 UNION 3 SELECT id, name ,address FROM animal2; ID NAME ADDRESS ---------- -------------------- -------------------- 001 いるか 海 002 うさぎ 陸 003 ぺんぎん 空 004 いるか 海 005 ふくろう 空
想定どおりのレコードが取得できていますね\(^o^)/
「UNION ALL」で重複行を取得する。
冒頭でも記述したように「UNION」は重複行を取得しません。そもそも集合演算子は、重複行を取得しません。
重複行を取得したい場合には、「ALL」オプションを使います。
「UNION ALL」の構文
以下が、「UNION ALL」の基本的な構文です。
SELECT 列1, 列2,・・・ FROM <テーブル名1> UNION ALL SELECT 列1, 列2,・・・ FROM <テーブル名2>;
「UNION ALL」のSQL
以下のSQLを実行してみましょう。
SELECT id ,name ,address FROM animal1 UNION ALL SELECT id ,name ,address FROM animal2;
「UNION ALL」の実行結果
SQL> SELECT id ,name ,address FROM animal1 2 UNION ALL 3 SELECT id ,name ,address FROM animal2; ID NAME ADDRESS ---------- -------------------- -------------------- 001 いるか 海 002 うさぎ 陸 003 ぺんぎん 空 004 いるか 海 001 いるか 海 002 うさぎ 陸 005 ふくろう 空 7行が選択されました。
想定どおりの結果ですね。重複行のID「001」の「いるか」とID「002」の「うさぎ」を取得しています。
「UNION ALL」の性能について
取得するレコードに重複がないと要件等から判明している場合は、「UNION ALL」を使用しましょう。性能面では「UNION」と比べて断然良いです。
理由は、「UNION」は重複行を削除するために一旦並べ替え(ソート)をしてしまうからです。並べ替えの発生しない「UNION ALL」が性能で軍配が上がるのは当然ですね\(^o^)/


コメント